배경 및 목적
내가 몸담고 있고 개발중인 솔루션에서는 업무 자동화를 위한 워크플로우(Workflow) 라는 멋진 기능이 있다.
업무 프로세스라고도 칭하기도 하는데, 결재, 배포, 설계변경 등 업무 자동화가 필요한 곳에 활용되고,
순서도 기반이라 복잡한 비즈니스 로직을 효과적으로 시각화 할 수 있고 많은 경우의 수를 감안해서 처리 할 수 있다는 강점이 있다.
온프로미스로 커스텀 해서 들어가는 프로젝트의 경우에는 고객사마다 조금씩 다른 비즈니스 로직에 맞추어 커스텀하고 개발해서 제공하기도 하는데,
워크플로우 플렛폼 개발 담당자이자 커스텀 담당자로써 매번 느끼는 거지만 고객사마다 업무 프로세스는 정말 천차만별이다..😵💫
워크플로우를 통해 비즈니스 로직을 순서도로 만들게 되면, 업무 흐름이 시각적으로 단순화 되어서 직관적으로 이해하기도 편하고 프로세스 진행 현황 확인도 편해지게 된다. 그치만 단순해 보이는 느낌과 다르게 굉장히 많은 경우의 수들이 있기 때문에 워크플로우 테스트는 이 모든 경우의 수 까지 테스트 시나리오로 만들어서 전부 확인하는 과정을 거쳐야 워크플로우에 문제가 없는지 완벽하게 보증 할 수 있다.
이 모든 테스트 시나리오를 워크플로우를 보면서 직접 적어내려가기에는 정확도와 효율이 매우 떨어지기 때문에 알고리즘을 통해 자동으로 모든 경우의 수를 추출 할 수 있는 방법을 고민하다가 DFS를 적용해보는 시도를 하게 되었다.
더 효율적인 방법이나 디자인 패턴이 있으면, 제발! 제발 아이디어를 댓글로 제공해 주시면 매우 감사하겠습니다..
워크플로우
워크플로우 기능이란
워크플로우 기능은 업무 프로세스를 자동화하고 최적화하는 도구로, 작업의 순서와 규칙에 따라 작업을 효율적으로 조정한다.
업무의 이동, 승인, 통지 등의 단계를 자동으로 실행하며, 업무 흐름을 직관적으로 만들어 업무 프로세스의 효율성, 일관성 및 직관성이 향상된다.
워크플로우 작성 시 모든 경우의 수 계산하기
워크플로우는 시작과 끝이 정해져있고 유량이 1인 그래프 형태를 갖추고 있다.
이러한 그래프 구조에서 시작 노드부터 종료 노드까지의 모든 가능한 경로를 추출하면 모든 테스트 시나리오의 경우의 수 또한 추출할 수 있을 것이다.
이를 위해 먼저 그래프 탐색의 종류를 간단히 확인하고,
테스트 시나리오 추출에 깊이 우선 탐색 DFS 알고리즘을 적용해보겠다.
그래프 탐색
워크플로우와 그래프는 약간의 차이점이 있다.
그래프 탐색은 보통 시작 노드는 정해도 종료노드가 고정되어 있지는 않는데,
워크플로우는 시작 노드와 종료 노드가 고정되어 있다.
어차피 워크플로우 개발 시에는 무조건 END 노드로 종료되게 개발하기 때문에 DFS 적용 시에는 별다른 조치를 해 줄 필요는 없지만, 워크플로우가 그래프보다는 제약조건이 좀 더 있다는 포인트는 짚고 넘어가겠다.
깊이 우선 탐색(DFS, Depth-First Search)
DFS는 그래프나 트리와 같은 자료구조에서 사용되는 탐색 알고리즘 중 하나로, 특정 경로를 따라 최대한 깊이 들어가면서 탐색을 수행하는 방식이다.
모든 가능한 경로를 탐색할 수 있기 때문에 깊이 우선 탐색 방식이 적합하다고 판단했다.
너비 우선 탐색(BFS, Breadth-First Search)
그래프 너비 우선 탐색(BFS)은 시작 노드에서 인접한 모든 노드를 우선적으로 방문하는 탐색 알고리즘이다.
시작 노드에서 인접한 노드를 모두 방문한 후, 해당 노드들의 인접 노드들을 차례로 방문한다.
이 과정은 목표 노드가 발견될 때까지 반복되며, 최단 경로를 찾거나 특정 노드를 찾는 데 사용된다.
깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)의 차이
깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)은 그래프를 탐색하는 두 가지 주요 알고리즘이다.
DFS는 한 경로를 끝까지 탐색한 후 다른 경로를 찾아나가며 깊게 들어가는 방식으로 동작하고,
반면에 BFS는 시작 노드에서 인접한 노드들을 우선적으로 모두 탐색하며, 레벨 단위로 퍼져나가는 방식으로 동작한다.
DFS는 스택(Stack)이나 재귀를 사용하여 구현되며, BFS는 큐(Queue)를 활용한다.
따라서, DFS는 깊은 부분을 우선적으로 탐색하고자 할 때, BFS는 넓은 영역을 우선적으로 탐색하고자 할 때 주로 사용되는 편이다.
깊이 우선 탐색(DFS)의 동작 방법
깊이 우선 탐색(DFS)은 아래와 같은 순서로 동작한다.
- 시작 노드 선택: 탐색을 시작할 노드를 선택한다.
- 노드 방문 표시: 시작 노드를 방문했다고 표시하고, 해당 노드를 스택(Stack)이나 재귀 호출의 기록에 추가한다.
- 인접 노드 탐색: 현재 방문한 노드의 인접 노드 중에서 아직 방문하지 않은 노드를 찾는다.
- 깊게 들어가기: 방문하지 않은 인접 노드가 있다면, 해당 노드를 선택하고 1~3단계를 반복한다. 선택한 노드를 방문 표시하고, 스택이나 재귀 호출의 기록에 추가한다.
- 탐색 불가 시 되돌아감: 더 이상 방문하지 않은 인접 노드가 없다면, 이전 단계로 돌아가서 이전 노드로 되돌아간다. 이때 스택이나 재귀 호출에서 이전 노드를 꺼내고, 해당 노드의 인접 노드 중 아직 방문하지 않은 노드를 찾아 다시 깊이 우선 탐색을 수행한다.
- 모든 노드를 방문할 때까지 반복: 스택이 비거나 모든 노드를 방문할 때까지 위 과정을 반복하여 그래프를 완전히 탐색한다.
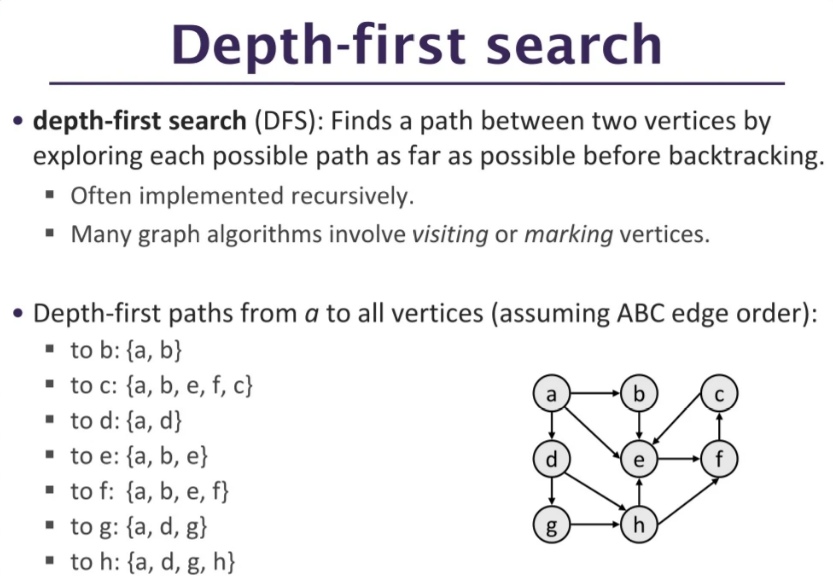 이미지 출처: PPT - Depth-first search PowerPoint Presentation, free download - ID:8160117
이미지 출처: PPT - Depth-first search PowerPoint Presentation, free download - ID:8160117
깊이 우선 탐색(DFS) 적용 아이디어
위의 깊이 우선 탐색(DFS)은 동작 시 시작노드에서 종료노드까지 도달한 경우의, 스택에 저장되어있는 경로를 하나의 테스트 케이스로 간주한다.
재귀 호출을 통한 작업을 통해 각각 하나하나의 테스트 케이스를 취합해 모든 경우의 수를 얻을 수 있을거라 예상했다.
간단한 비즈니스 로직의 워크플로우를 만들어서 적용해보도록 하자.
DFS 적용 검증
테스트용 워크플로우 만들기
DFS 알고리즘 적용해 보기 위해 간단한 비지니스 로직으로 테스트용 워크플로우를 만들려 한다.
비지니스 로직 예시
문서 결재 워크플로우를 만들기 위해 예시를 들어보겠다.
A사는 문서결재 업무를 워크플로우 기능을 이용해 구성하고 업무를 자동화하려 한다고 가정하자.
A사의 문서 결재 업무는 다음과 같은 조건이 충족되어야 한다.
- 문서는 작업중, 결재중, 승인됨, 재작업 의 상태를 가질 수 있습니다.
- 문서 결재가 모두 승인되면 문서는 승인됨 상태가 됩니다.
- 문서 결재가 진행중일 때 문서는 결재중 상태가 됩니다.
- 문서는 결재가 진행되기 전에는 작업중 상태입니다.
- 문서 결재가 반려되면 문서는 재작업을 통해 다시 문서 결재를 시작해야한다. 이 경우 상신자에게 재작업 임무가 주어지며 해당 재작업 임무를 완료하면 문서 결재가 다시 시작된다. 상신자에게 재작업 임무가 떨어질 때부터 재작업 임무를 완료하기 전까지 문서는 재작업 상태입니다.
- 문서 결재는 총 2개 단계의 승인자를 거쳐야하며 1단계는 매니저, 2단계는 최종 승인자로 구성되어있습니다.
- 문서 결재가 시작되면 1단계 승인, 2단계 승인을 거쳐 모든 단계에서 통과하면 문서 결재가 성공적으로 종료되며 승인됨 상태가 됩니다.
- 문서 결재를 올리는 상신자는 1단계 및 2단계에 어떤 승인자에게 문서를 결재받을것인지 직접 지정합니다.
- 문서 결재는 1단계 승인 진행 후 2단계 승인이 진행되는 선형적 방식으로 이루어집니다.
- 1단계의 매니저로부터 문서결재를 승인받지 못하면 해당 문서는 2단계인 최종 승인자에게 도달하지 못합니다.
- 1단계에 해당하는 매니저는 여러명이 될 수 있으며, 여러 매니저에게 승인을 받아야하는경우 모든 매니저에게 승인을 받아야 1단계 승인단계를 통과할 수 있습니다. 한사람의 매니저라도 해당 결재를 반려하면 1단계 승인을 받을 수 없습니다.
- 2단계에 해당하는 최종 승인자는 여러명이 될 수 있으며, 모든 최종 승인자에게 승인을 받아야 2단계 승인이 통과하고 문서 결재가 최종 승인되게 됩니다.
- 간단한 문서의 경우 2단계 승인자를 지정하지 않아도 되는 경우가 있습니다. 이 경우 1단계 승인자에 지정한 매니저에게만 승인받으면 문서 결재가 최종 승인됩니다.
- 모든 결재 프로세스에서 1단계 승인자에 할당된 매니저가 최소 한명 이상이 있다고 가정합니다.
매우 구구절절 복잡해 보이지만 비지니스 로직 중에서는 매우 간단하고 기본적인, 있을법한 요구사항들이다.
워크플로우 작성 예시
위의 비지니스 로직 예시에서 볼 수 있듯이, 문서 결재 시 고려해야하는 사항들을 글로 적으면 단계가 매우 복잡해 보인다. 조건문을 얼마나 써야 할지 감이 오지도 않고 아찔하다.
위의 고려 사항들을 순수 코드로 구현하고자 하면 그 복잡도와 분량은 엄청날 것이고, 향후 수정 또는 개선 사항들이 있을 때 유지보수 측면에서도 아주 부담스러울 수 있다.
워크플로우 기능은 복잡한 비지니스 로직을 순서도로 정리하여 복잡한 업무 프로세스를 쪼개어 관리할 수 있으며 업무 흐름을 직관적으로 만들 수 있다고 얘기 해왔는데 직접 결과를 확인해보자.
위의 고려 사항들이 포함된 비지니스 로직을 워크플로우 기능으로 만들어 보겠다.
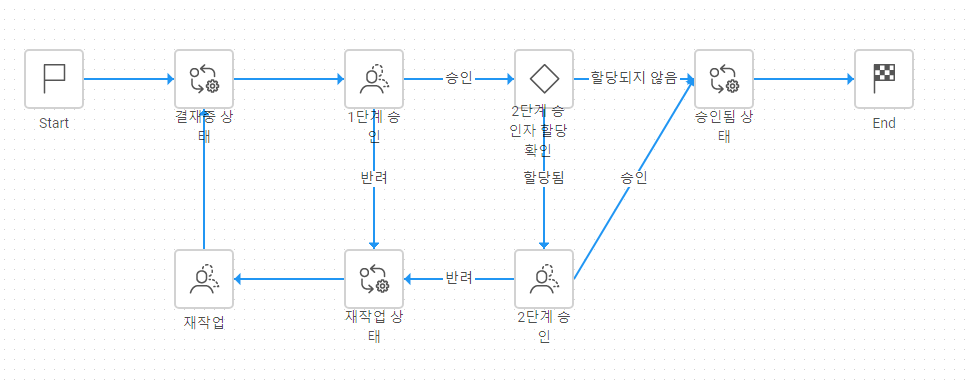
의 그림은 위에서 예시로 설명된 비지니스 로직에서 충족되어야하는 모든 조건이 만족하는 간단한 워크플로우이다.
직관적이고 이해하기 편한 것을 확인할 수 있다.
하지만 이 워크플로우의 모든 경우의 수를 테스트 한다면?
물론 눈으로 화살표를 따라가면서 적어서 정리할 수는 있지만 정확하고 효율적이라고 할 수는 없다.
본 글의 처음에서 이야기 해왔던, DFS를 적용해서 워크플로우 테스트 경우의 수를 추출하기 위한 고민과 그 필요성에 대해 이해하시게 되셨으리라 믿는다..
이제 이 워크플로우 예제로 DFS 알고리즘을 적용해 보자.
DFS 코드 작성
깊이 우선 탐색(DFS) 알고리즘을 코드적으로 구현하기 위해서는 그래프 클래스, 그래프를 구성하는 노드 클래스, 실질적인 검색을 수행하는 DFS 클래스가 필요하다.
각각의 클래스를 작성하고, 최종적으로 워크플로우에 적용해보겠다.
노드 클래스
그래프의 노드(Node)란 그래프에서 하나의 요소를 나타내는 기본 단위이다. 노드는 그래프의 한 지점을 나타내며, 이 지점은 데이터를 저장할 수 있는데, 고유한 식별자(일반적으로 숫자 또는 문자열)와 해당 노드와 연결된 다른 노드의 정보를 포함하는 인접 리스트와 같은 구조를 데이터로 포함할 수 있다.
다만 일반적인 노드 클래스와 다르게 위의 워크플로우를 표현하기 위해 고려되어야 할 점은, 워크플로우의 링크에는 String 형태의 링크 이름이 있다는 점 이다. 이를 표현하기 위해 일반적인 노드 클래스와는 다르게 인접 노드를 리스트를 구성할 때 링크이름과 인접노드를 함께 저장하는 Map 형태의 데이터를 담게 조정했다.
class Node {
// id: 노드의 고유 식별자
private int id;
// name: 노드의 이름 또는 레이블
private String name;
// adjNodeList: 인접 노드 정보를 담는 리스트. 현재 노드와 인접 노드를 연결하는 링크의 이름도 함께 저장함.
// Map<linkName:String, node:Node>
private List<Map<String, Node>> adjNodeList;
public Node(int id, String name) {
this.id = id;
this.name = name;
this.adjNodeList = new ArrayList<>();
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public List<Map<String, Node>> getAdjNodeList() {
return adjNodeList;
}
public void addAdjacentNode(String linkName, Node node) {
Map<String, Node> link = new HashMap<>();
link.put(linkName, node);
adjNodeList.add(link);
}
}그래프 클래스
해당 알고리즘을 위한 그래프는 단순하게 노드들의 집합체로써만 기능하게 하겠다.
class Graph {
// Map<id:Integer, node:Node>
private Map<Integer, Node> nodes;
public Graph() {
nodes = new HashMap<>();
}
public void addNode(Node node) {
nodes.put(node.getId(), node);
}
public Node getNode(int id) {
return nodes.get(id);
}
}DFS 클래스
스택과 재귀 호출을 이용한 DFS 검색 알고리즘이 구현된 DFS 클래스를 작성해보자.
DFS 클래스는 그래프와 노드의 방문여부를 기록하고 체크할 Set 타입의 변수를 속성으로 가지고있다.
또한 깊이 우선 탐색을 위해 스택을 사용한 재귀적인 탐색을 하는 메소드와 스택에 저장된 노드정보를 이용하여 경로 정보를 생성하는 메소드를 가지고 있다.
public class DFS {
// 그래프
private Graph graph;
// 방문한 노드 집합
private Set<Node> visited;
/**
* DFS 클래스의 생성자
*
* @param graph 그래프 객체
*/
public DFS(Graph graph) {
this.graph = graph;
visited = new HashSet<>();
}
/**
* 시작 노드부터 목표 노드까지의 모든 경로를 찾는 재귀적인 깊이 우선 탐색(Depth-First Search) 알고리즘
*
* @param node 현재 노드
* @param target 목표 노드
* @param linkName 현재 노드와 다음 노드를 연결하는 링크의 이름
* @param allPaths 모든 경로가 저장될 리스트
* @param stack 현재까지의 경로가 저장된 스택
*/
public void findAllPaths(Node node, Node target, String linkName, List<List<Map<String, Node>>> allPaths, Stack<Map<String, Node>> stack) {
// 현재 노드를 방문한 것으로 표시
visited.add(node);
// 현재 노드와 해당 링크 정보를 스택에 추가
Map<String, Node> stackMap = new HashMap<>();
stackMap.put(linkName, node);
stack.push(stackMap);
// 목표 노드에 도달했을 경우, 경로를 생성하고 리스트에 추가
if (node == target) {
allPaths.add(createPath(stack));
} else {
// 현재 노드의 인접 노드들을 탐색하며 재귀적으로 경로를 찾음
for (Map<String, Node> adjNode : node.getAdjNodeList()) {
for (Map.Entry<String, Node> entry : adjNode.entrySet()) {
String nextLinkName = entry.getKey();
Node nextNode = entry.getValue();
// 방문하지 않은 인접 노드일 경우 재귀 호출
if (!visited.contains(nextNode)) {
findAllPaths(nextNode, target, nextLinkName, allPaths, stack);
}
}
}
}
// 백트래킹을 위해 방문 여부를 되돌림
visited.remove(node);
// 현재 노드를 스택에서 제거
stack.pop();
}
/**
* 스택에 저장된 노드를 이용하여 경로를 생성
*
* @param stack 스택에 저장된 노드 경로 정보
* @return 생성된 경로 리스트
*/
private List<Map<String, Node>> createPath(Stack<Map<String, Node>> stack) {
List<Map<String, Node>> path = new ArrayList<>();
// 스택에 저장된 경로를 순회하며 경로 리스트를 생성
for (Map<String, Node> stackItem : stack) {
for (Map.Entry<String, Node> entry : stackItem.entrySet()) {
Map<String, Node> nodeMap = new HashMap<>();
nodeMap.put(entry.getKey(), entry.getValue());
path.add(nodeMap);
}
}
return path;
}
}예시 워크플로우 그래프로 선언하기
위에서 만든 워크플로우를 그래프로 선언해보자.
워크플로우를 그래프로 선언하기 위해서는 각 노드에 id를 붙여야 한다. 각 노드를 넘버링 하고 그래프로 선언해보겠다.
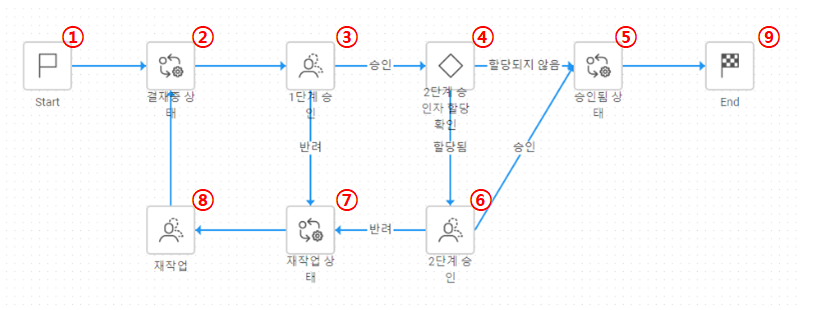
워크플로우 에디터의 데이터를 그래프로 변환하는 변환 클래스가 있으면 더 깔끔하겠지만, 일단 본 글에서는 DFS 적용 검증이 목표임으로 좀 무식하게 옮겨적겠다.
Graph graph = new Graph();
// 노드 생성
Node node1 = new Node(0, "START");
Node node2 = new Node(1, "결재중 상태");
Node node3 = new Node(2, "1단계 승인");
Node node4 = new Node(3, "2단계 승인자 할당 확인");
Node node5 = new Node(4, "승인됨 상태");
Node node6 = new Node(5, "2단계 승인");
Node node7 = new Node(6, "재작업 상태");
Node node8 = new Node(7, "재작업");
Node node9 = new Node(8, "END");
// 인접 노드 추가
node1.addAdjacentNode("COMPLETE", node2);
node2.addAdjacentNode("COMPLETE", node3);
node3.addAdjacentNode("승인", node4);
node4.addAdjacentNode("할당되지 않음", node5);
node3.addAdjacentNode("반려", node7);
node4.addAdjacentNode("할당됨", node6);
node6.addAdjacentNode("승인", node5);
node6.addAdjacentNode("반려", node7);
node7.addAdjacentNode("COMPLETE", node8);
node8.addAdjacentNode("COMPLETE", node2);
node5.addAdjacentNode("COMPLETE", node9);
// 그래프 생성
graph.addNode(node1);
graph.addNode(node2);
graph.addNode(node3);
graph.addNode(node4);
graph.addNode(node5);
graph.addNode(node6);
graph.addNode(node7);
graph.addNode(node8);
graph.addNode(node9);
// 시작 노드와 목표 노드 설정
Node startNode = node1;
Node targetNode = node9;링크 이름이 포함된 인접노드로 구성된 그래프가 생성되었고, 이를 기반으로 DFS 클래스를 사용하여 모든 경로 정보를 저장하고, 저장된 경로 정보를 출력해보도록 하겠다.
DFS dfs = new DFS(graph);
List<List<Map<String, Node>>> allPaths = new ArrayList<>();
Stack<Map<String, Node>> stack = new Stack<>();
dfs.findAllPaths(startNode, targetNode, "", allPaths, stack);
// Print all paths
int i = 0;
for (List<Map<String, Node>> path : allPaths) {
++i;
System.out.print("CASE " + i + " : ");
for (Map<String, Node> node : path) {
for (Map.Entry<String, Node> entry : node.entrySet()) {
String linkName = entry.getKey();
String nodeName = entry.getValue().getName();
// linkName이 비어있지 않은 경우 링크 이름을 포함하여 출력
String linkPrefix = linkName.length() > 0 ? " >(" + linkName + ")> " : "";
System.out.print(linkPrefix + nodeName);
}
}
System.out.println();콘솔에 결과가 출력된다.
DFS 결과 확인

어떤 노드와 링크를 거쳐 시작 노드에서 종료 노드까지 도달 하는지에 대한 모든 경우의 수가 출력된 것을 확인할 수 있었다.
괄호 안에 표시된 내용은 링크의 이름이다.
마무리
콘솔에 조악하게 출력하긴했지만, 복잡한 워크플로우에서 테스트 해야하는 모든 경우의 수가 자동으로 추출됨에 만족한다.
본 글에서 테스트한 경우의 수는 2개이지만, 노드 몇개만 더 추가되도 케이스는 기하 급수적으로 늘어난다.
이런 류의 그래프 데이터를 통한 경우의 수 추출이 필요한 경우 데이터를 그래프 객체로 변환하는 변환부만 조금 더 손보면 아쉬운대로 쓸만한 테스트 시나리오 추출기가 되지 않을까 싶다.
지금으로써는 이 방식이 나한텐 최선이지만, 아쉬운 마음에 글의 첫부분에서도 이야기 했지만 다시 한번 얘기한다.
더 효율적인 방법이나 디자인 패턴이 있으면, 아이디어를 댓글로 제공해 주시면 매우 감사하겠습니다..